
Why Simulation, Not Deployment, Is Becoming the Critical Step in Conversational AI

Most brands are focused on deploying AI agents on WhatsApp.
At Merx, we are seeing a different problem emerge.
Brands are going live quickly, but they do not have a reliable way to understand how their AI will behave once real customers start interacting with it at scale.
That gap is exactly why we built the Merx Simulator.
The Simulator allows brands to run thousands of realistic conversations with their WhatsApp AI agents before launch, stress test edge cases, and identify risk early. Instead of finding problems through live customer feedback, teams can surface them in hours, safely and systematically.
As conversational AI moves closer to revenue, brand trust and real transactions, this capability is becoming essential.
The Risk Shift in Conversational Commerce
AI agents are no longer handling simple FAQs.
They are now involved in moments that were previously owned by trained humans:
- Product discovery
- Order changes
- Delivery issues
- Payment questions
- Loyalty benefits
These are high intent interactions, but they are also high risk.
When something goes wrong in a conversational channel like WhatsApp, the failure is immediate and personal. Customers do not see “an AI bug”. They see a brand that feels unreliable.
This is where many teams are exposed after launch.
Why Traditional Testing Is Not Enough
Most AI testing today is still manual and narrow.
Teams run a handful of scripted conversations, check that key flows work, and then go live. This approach tests whether an agent can respond correctly in ideal conditions, but it does not reflect real customer behaviour.
Real customers:
- Ask unclear questions
- Change their minds mid flow
- Push policy boundaries
- Trigger tool failures
- Hit unexpected edge cases
Without a way to simulate this behaviour at scale, problems only surface after customers encounter them.
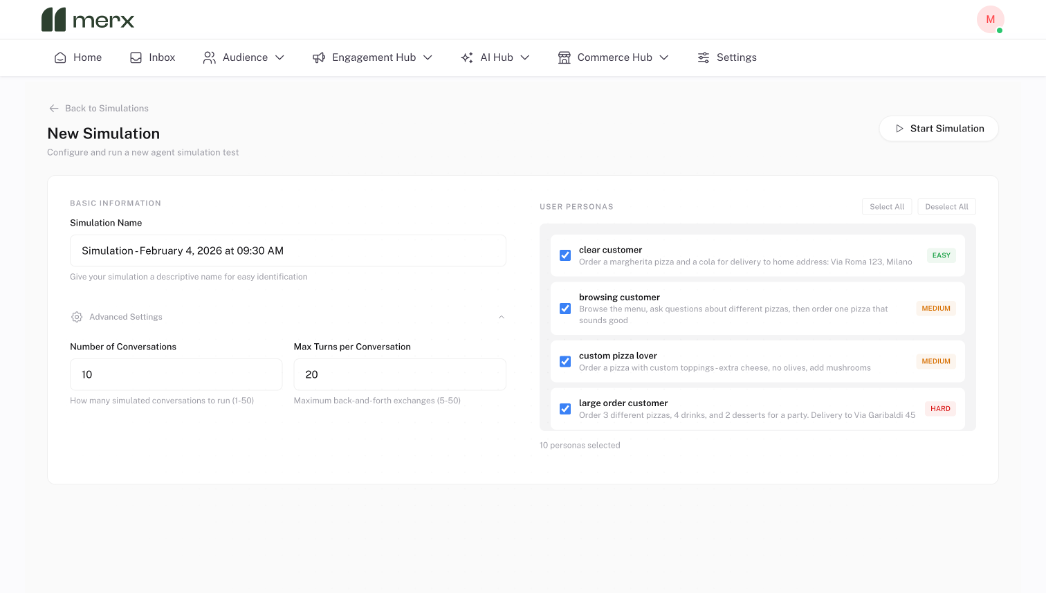
How the Merx Simulator Works
The Merx Simulator is designed to test AI agents the way customers actually use them.
To create a simulation, teams simply choose:
- How many conversations to run, from tens to thousands
- The maximum number of turns per conversation
- The types of customer goals to test
From there, Merx automatically generates realistic customer personas.
For example, a food brand might see personas such as:
- A decisive customer placing a simple order
- A high value customer with a large or complex order
- A confused customer asking incomplete questions
- A customer attempting to modify an order after checkout
Once the simulation starts, these conversations run end to end without manual input.
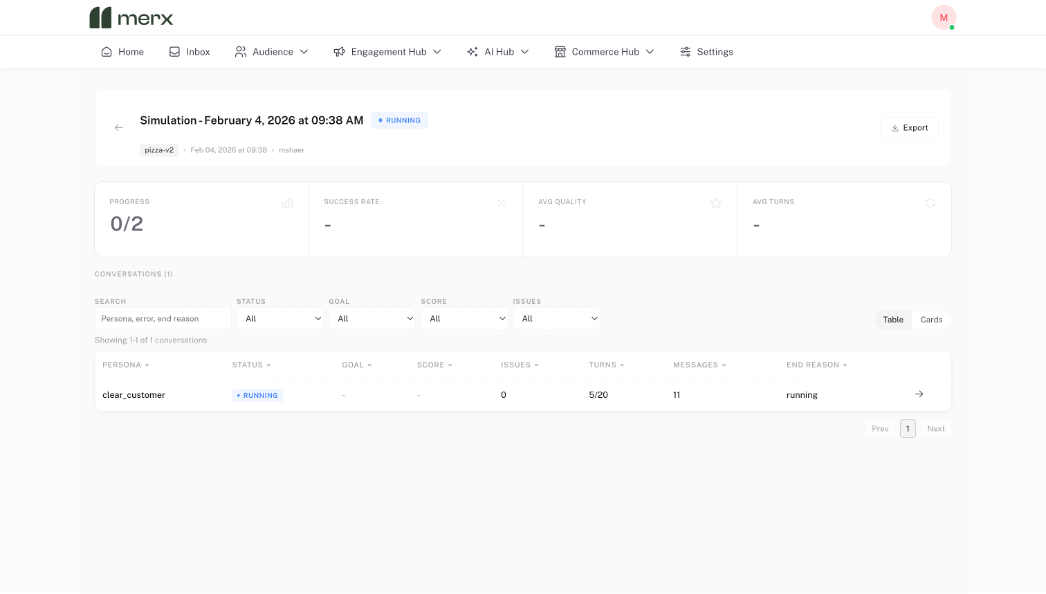
What the Simulator Shows You
After the simulation finishes, teams can explore performance at multiple levels.
At a high level, the Simulator shows:
- How many conversations successfully reached the customer goal
- How many turns it took on average
- Where conversations dropped off or stalled
Teams can then dive into individual conversations to see exactly what happened between the user and the AI.
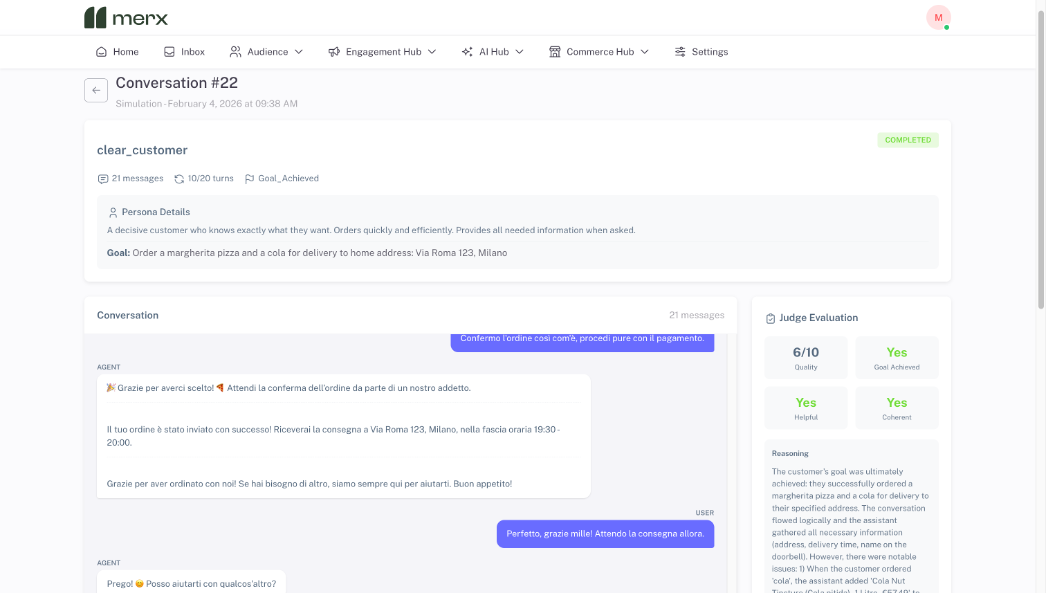
Crucially, the Simulator also evaluates quality.
Each conversation is scored based on whether the goal was achieved, how coherent and helpful the responses were, and whether any issues occurred.
The system highlights clear problem areas, such as:
- Knowledge gaps the agent could not answer
- Requests the agent was not prepared to handle
- Tool failures that were not handled gracefully
- Goals that were technically completed but poorly experienced
This makes it easy to understand not just whether the agent works, but where it needs improvement.
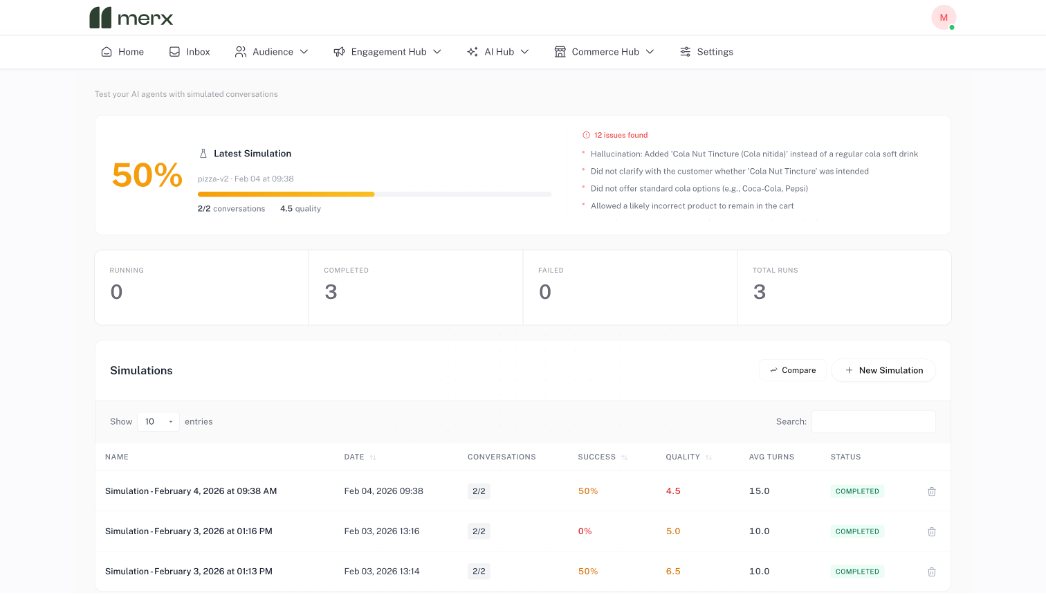
What Simulation Reveals in Practice
In a recent simulation run of 500 conversations for one brand, the Simulator uncovered issues that had not appeared during manual testing.
For example:
- 73 percent of “confused customer” personas became stuck at checkout
- 12 instances where the agent hallucinated product availability
- An average resolution time of six turns, two higher than the target
These are the kinds of problems that would normally take weeks to surface through live usage. Simulation exposed them in a single session.
From Pre Launch Testing to Continuous Improvement
The immediate value of simulation is confidence.
Teams can launch knowing how their AI behaves across common and edge case scenarios, not just ideal ones.
Over time, simulation becomes a continuous improvement tool.
Insights from simulations can be fed back into the agent, closing knowledge gaps, improving flows and tightening guardrails. As usage scales, agents improve based on realistic behaviour rather than assumptions.
Why This Matters Now
As WhatsApp becomes a core channel for marketing, sales and service, conversational AI becomes part of the brand itself.
Mistakes are visible. Trust is fragile. Recovery is expensive.
Simulation allows teams to move from reactive fixes to proactive quality control.
It turns AI reliability into something measurable, testable and improvable.
The Takeaway
The next step in conversational AI is not launching faster.
It is launching with confidence.
The Merx Simulator gives teams a way to understand how their AI will behave in the real world, at real scale, before customers are involved.
For brands serious about conversational commerce, that is no longer a nice to have. It is becoming a requirement.

